


A Necessary Tech History of ChatGPT -- The Five Most Important Questions about ChatGPT, Part 2
If you know LLMs, you can jump to the summary diagram in the end.

Introduction: A Brief History of ChatGPT
Before we start asking questions, some necessary technical background is needed. We will focus on two summary articles, trying to capture the main points:
1. The essence of large language model technology (link)
2. Where ChatGPT's various superpowers come from (link)
If you are a techincal folk that not only knows ML, but also knows LLM, you can go directly to the summerizing diagram at the end of this chapter.

Here, we emphasize "emergence" once more. After GPT-3, many capabilities have "emerged." That is, they are not linearly developed or predictable, but suddenly appear. As for whether this was bound to happen for the people at OpenAI, or completely unexpected, we do not know. These "emerging" capabilities, especially the "crow ability", set ChatGPT apart from previous AI paradigms and will be the focus of our discussion. The "emergence" is also a fascinating aspect of large language models; we find that these abilities suddenly appear as the amount of data and model size increase, but there is only speculation and no consensus on how they emerge. This article(https://yaofu.notion.site/A-Closer-Look-at-Large-Language-Models-Emergent-Abilities-493876b55df5479d80686f68a1abd72f#b8609bc4b61045db924002de43ae138d) provides a comprehensive summary and comparison.
The following image shows the evolutionary history from GPT-3 to ChatGPT best derived from OpenAI's public information.
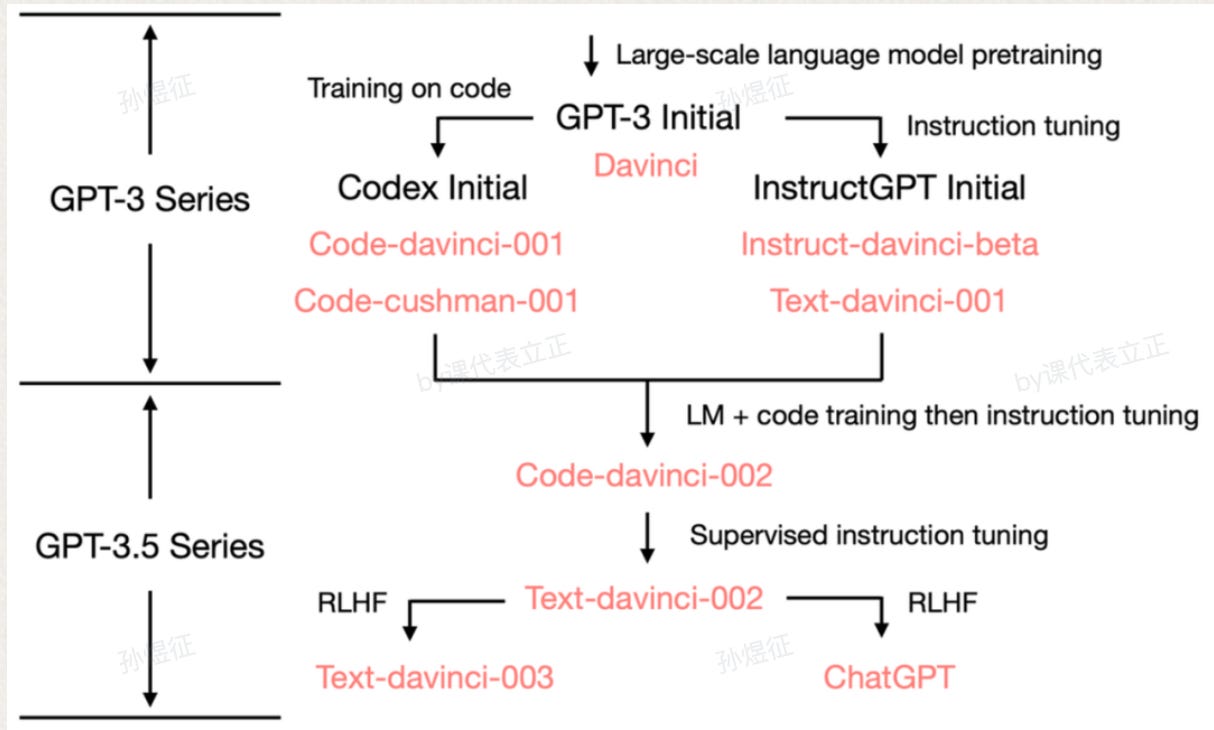
Combining the above image and table, let's briefly organize:
1. GPT-3 is an impressive LLM. This podcast from two and a half years ago offers an early-adopter's perspective. Although GPT-3 can do in-context learning, it didnt' qualify as a "paradigm shift" yet.
2. GPT-3.5, through InstructGPT's methododogy + code reading, emerged the "crow ability (explained in the first question)", resulting in a "paradigm shift". However, GPT-3.5 has not yet found a suitable application interface and does not cater to human preferences.
3. ChatGPT, with the help of RLHF, has found a reasonable interface between GPT-3.5 and human natural language, unlocking the prospects for model application.
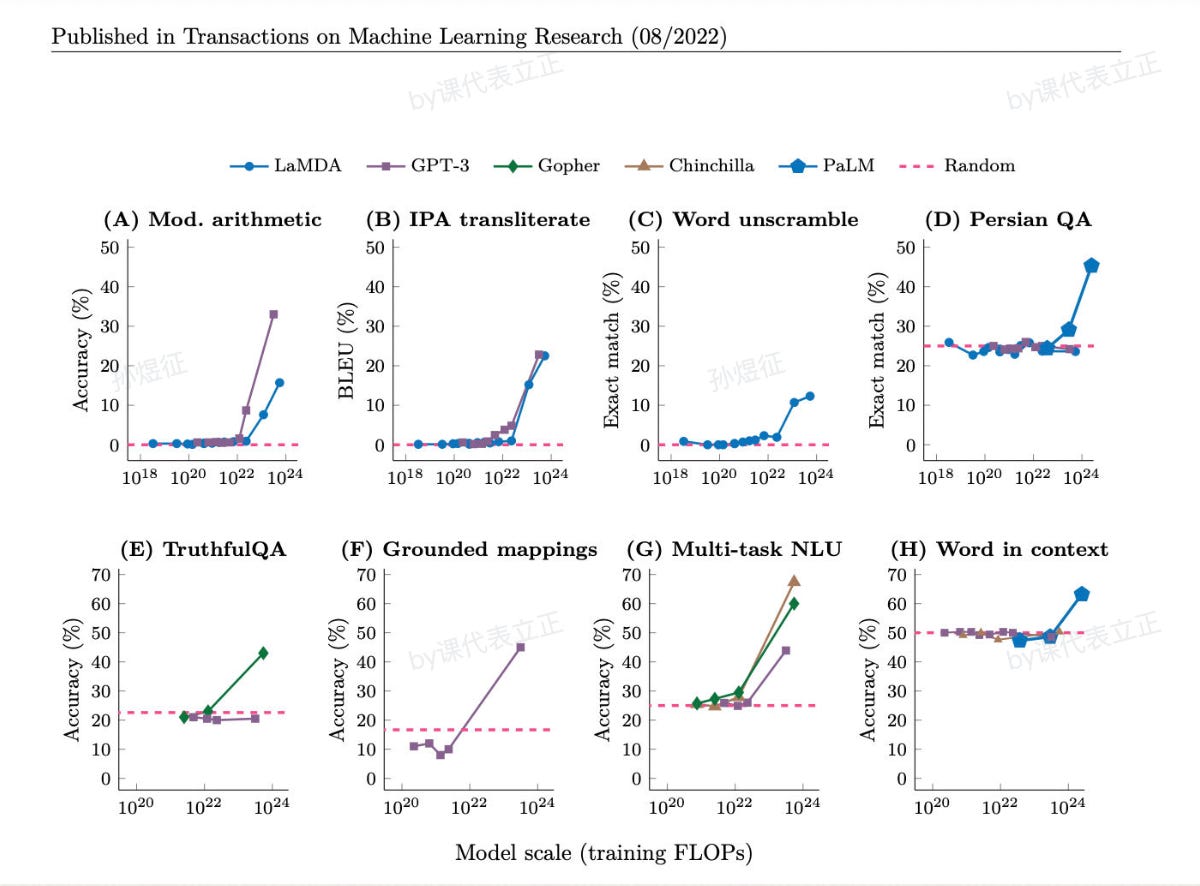
Emerging Capabilities of Various LLMs
Thus, we should remember that the powerful model is GPT-3.5, and the powerful application method is ChatGPT. The application method is relatively easy to replicate: while RLHF is challenging, it is not too difficult. The real challenge lies in reproducing the "crow ability". If we want to focus on whether we can create ChatGPT, we need to focus on how far other LLMs are from the "crow ability" of GPT-3.5. Applying a ChatGPT-like approach to an LLM without the "crow ability" is just a poor imitation, but it is likely a common method that many companies will adopt.
Here, we say that "the application method is relatively easy to replicate," but that does not mean the application method is not disruptive. When the iPhone first appeared, many people thought there was no revolutionary technology, just a nice integrated solution.

However, what those people didn't see was that iPhone was the first "smartphone cater to human behaviors" rather than a "smartphone cater to uses cases". The iPhone's interaction methods and various sensors have gradually made it an extension of the human body, a more efficient and informative organ. ChatGPT is already approaching the ultimate form of human access to computing power and data, and of course, its application method itself is powerful enough. We will discuss this further in the second question, "Which jobs will ChatGPT replace?" For now, let's just stay with the conclusion that ChatGPT is a great UI, but easy to replicate. GPT-3.5 is difficult to replicate, and often underestimated.
This also involves an important digression. In our discussion, we found that many senior AI practitioners, if they do not delve into the details of LLMs but instead use their past experience to speculate on the source of ChatGPT's capabilities, can develop serious misunderstandings. We have summarized these misunderstandings, and found that they mostly occur in the context of in-context learning. Especially the term "fine tuning" is too broad that got people confused. So let's dedicate a sub-chapter to clairfy this.
Important Digression - Why do AI practitioners have misconceptions about ChatGPT?
Past NLP models were trained for specific tasks and data. Therefore, the better the data quality, the better the model's performance. So we call them "data-centric" AI. Ideally, there should be only correct labeling and no incorrect labeling in the training set. A key difference with large language models is that "more data" is better. The amount of data is important, and the quality of data is defined by "more informative text", but we don't require specific labeling as we did before.
Fine tuning in traditional ML models means changing the weight of the model. When face new tasks or even new data distribution, you need to change the weight of the model to optimize its loss function, thus creating and applying a new model. The new model probably, if not garenteed, to perform worse on existing tasks, thus further limiting its application.
The emergence of in-context learning capabilities in GPT-3 (now also present in other large models like Google's PaLM, although it is uncertain whether GPT-3 was the first to emerge with this ability; corrections are welcome) is fundamentally different from the aforementioned paradigm. With in-context learning, the pre-trained model does not change, yet it can perform better on new data. Research even found that if you give a large model a set of examples with correct overall relationships, it can still produce correct results when the specific order of those relationships is changed. This is truly amazing. To emphasize again, the model has not changed, it has not been retrained, but it can "understand" new data and perform better!
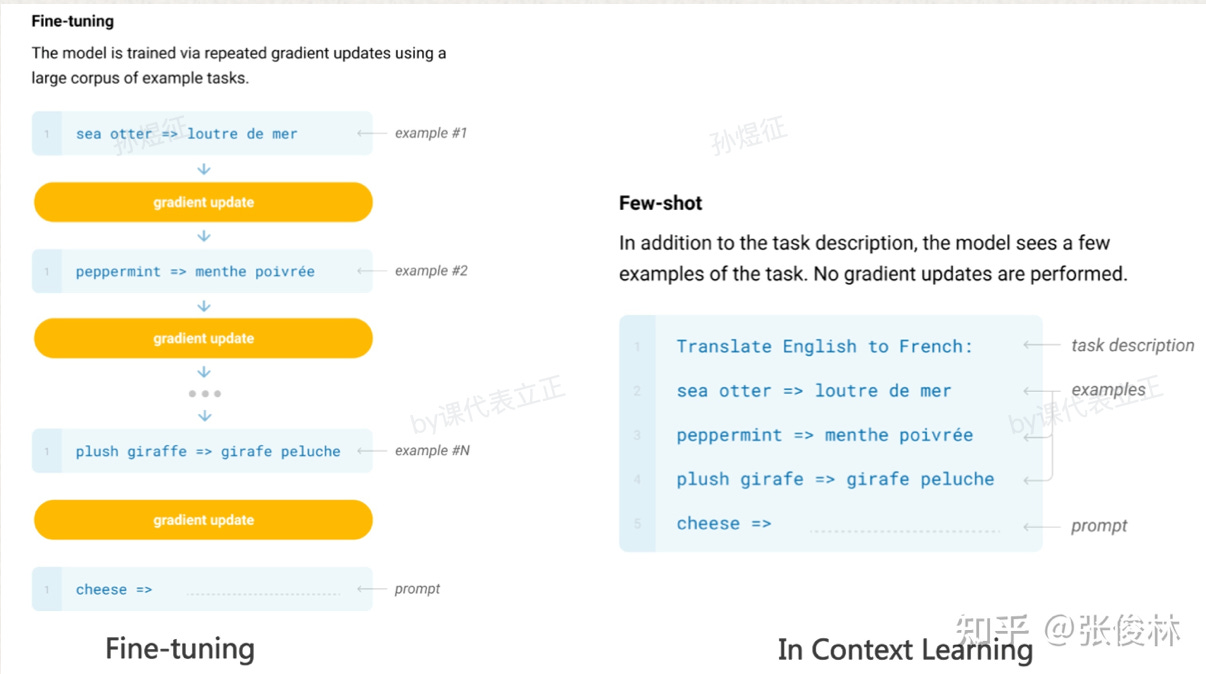
Next comes something even more incredible. With the GPT-Codex version unlocking reasoning capabilities, and the introduction of the instruct method by InstructGPT, their combined ChatGPT builds on in-context learning, demonstrating an ability to understand, reason, and deduce. We will elaborate on this in the next section. To save space, even though the capabilities emerged on GPT-3.5, we will refer to ChatGPT from here on.
An Important Relationship Diagram to Summerize This Chapter

I created a diagram to summerize this chapter. Please note a few points:
· Traditional ML use new data to iterate itself
· Pre-trained large models is to use a single large model to solve all problems. The model itself does not change
· Although InstructGPT and ChatGPT change the parameters of the underlying pre-trained large models, it:
· Is "processing" rather than "iterating"
· Is "activating" some of GPT-4's abilities, rather than "granting" GPT-4 any new capabilities
· Is "aligning" GPT-4 with human preferences, rather than "training" GPT-4
· New Bing is achieved based ChatGPT. When deducing what's possible with ChatGPT, we dont' need to speculate. We just need to imagine what if OpenAI opened its offering to Microsoft to the general public
Hope it’s helpful. Now that we get through all the necessary technical details. We can start dive into the important questions.